作者:齐木 七锋
背景
ACID 事务是关系型数据库一个重要的特性,也是 NewSQL 数据库最大的挑战之一。PolarDB-X是一款基于云架构理念,并同时支持在线事务处理与在线分析处理 (Hybrid Transactional and Analytical Processing, HTAP)的融合型分布式数据库产品。因此,对PolarDB-X来说,支持分布式ACID事务是必须的。
事务ACID概念
数据库英文为DataBase,是由Data + Base两个单词组成,可以理解为存放数据的仓库,最早数据库的诞生也是为解决数据的记账问题,要充分理解ACID的概念,可以从最朴素的转账业务看下。
转账案例:
A账户余额有100元,B账户余额0元,在这个基础上A向B转账40元,流程如下:
1、查询A账户余额,看金额是>=40元。
2、满足条件则先从A账户扣款40元(当前A余额=60、当前B余额=0)
3、然后再向B账户增加40元(当前A余额=60、当前B余额=40)
在这个案例中,我们分别看一下ACID在其中扮演的一些要求:
- 持久性 (Durability)。持久性是指一旦事务成功提交后,只要修改的数据都会进行持久化,不会因为异常、宕机而造成账户余额和转账信息的丢失。通常处于性能考虑数据库会进行内存写入的优化,避免数据的每次操作都进行写盘操作,数据库通常会借助于WAL日志(比如redo log)来满足持久性的要求。
- 原子性(Atomicity)。一个事务必须是一系列操作的最小单元,这系列操作的过程中,要么整个执行,要么整个回滚,不存在只执行了其中某一个或者某几个步骤。对应到案例中,原子性就代表「检查余额、转账、到账」三个步骤,这三个步骤就是一个整体,少了任何一个都不能称为一次转账。尤其在分布式事务模型下,多个分片一般会通过2PC策略保持一个状态协同。
- 一致性(Consistency)。事务的一致性要保证数据库整体数据的完整性和业务的数据的一致性,初看和原子性有一些相似的语义。对应到案例中,一致性会要求业务查询A/B账号时看到100/0 或 60/40的余额状态。
- 隔离性(Isolation)。事务的隔离性是指并发事务操作时,事务之间不会互相影响,初看是和前三个定义不对齐,其定义更多的是从技术实现角度考虑,一直没有统一的标准,不同数据库厂商从自己的实现角度会有不一样的行为。
原子性和一致性的区别?
原子性和一致性都要保证一个数据的多个操作整体的成功或者失败,初看两者有一些相似的语义,其实细究一下还是略微有一些区别,原子性主要面向数据库Write的行为定义,而一致性主要面向Read的行为定义。
拿实际例子来说,在分布式场景下如果涉及多节点的数据操作,在微观世界里就不能保障多节点的操作发生在同一时刻,一定是有细微的时间差,在这个时间差内如果用高并发Read操作是否就会看到转账过程中不一致的余额状态?因此数据库技术通常会借助锁机制或者MVCC多版本来实现一致性的行为。比如通常的分布式2PC,会在第一阶段prepare加锁,确保在第二阶段部分节点提交时,剩余部分节点未提交的数据会通过加锁,避免高并发Read操作读到中间提交一半状态的数据。
隔离级别的技术演进?
隔离级别的发展比较有故事性,不同数据库产商有各自的实现,缺乏统一的标准。
- 在1992年ANSI首先尝试指定统一的隔离级别标准,当时主要是基于锁机制来实现事务的并发控制隔离,定义了脏读、不可重复读、幻读的异像,ANSI 92标准中指出可以解决这三类异像的事务隔离称之为"可串行化"。
- 在1995年,微软的Jim Gray研究员们在《A Critique of ANSI SQL Isolation Levels》论文中批判了ANSI标准,新增了Lost Update(更新丢失)、Read/Write Skew(读写偏序)的异像场景,同时正式提出基于MVCC的快照隔离级别SI。而当时的Oracle是第一个在商业数据库中应用MVCC的技术,将其基于MVCC的SI隔离技术称之为"可串行化",主要是因为ANSI 92标准中对解决不可重复读、幻读异常定义的技术称之为可串行化,属于特定的文字游戏。
- 在1999年,在《Generalized Isolation Level Definitions》论文中提出了有向串行图DSG(Direct Serialization Graph)的隔离定义,可以在SI隔离级别的基础上解决Read/Write Skew(读写偏序)的异像问题,称之为SSI(Serializable Snapshot Isolation),主要的代表数据库为PostgreSQL/CockroachDB。
后续可以专门开一篇介绍隔离级别,这里就不详细展开具体的技术差异和实现细节。
分布式事务模型
在正式介绍PolarDB-X的分布式事务之前,也是非常有必要了解下当前世界上几种主流的分布式事务策略,因为关系数据库从80年代诞生开始,事务是区别于关系型数据库和NoSQL最本质的地方,众多学者一直在不断研究和优化事务的技术,尤其在互联网技术发展之后,数据出现爆炸式增长,分布式逐渐进入大家的视野。
Percolator模型
Percolator模型最早是在2010年,由Google工程师在解决索引增量构建的工程方案中第一次提出,具体可参见:《Large-scale Incremental Processing Using Distributed Transactions and Notifications》。Google Percolator实现上是在Bigtable基础上,在不改变 Bigtable 自身实现的前提下,通过行级事务和多版本控制,实现了 Snapshot Isolation 级别的跨行事务能力。
Percolator具体的实现细节网上已有蛮多的文章介绍,这里就不做详述,列举一下其设计的重点:
- 引入全局时钟 (timestamp oracle,简称TSO)。基于全局时钟分配一个全局单调增加的版本,实现分布式下事务多版本的事务id分配,在事务的开始start_ts和提交commit_ts进行可见性和冲突的判断。
- 基于KV的数据结构。为了支持分布式2PC的原子性提交,数据结构上将每一行上每个列的值都设计为data、write、lock的三个value,通过这样的数据结构满足事务一致性和隔离机制。
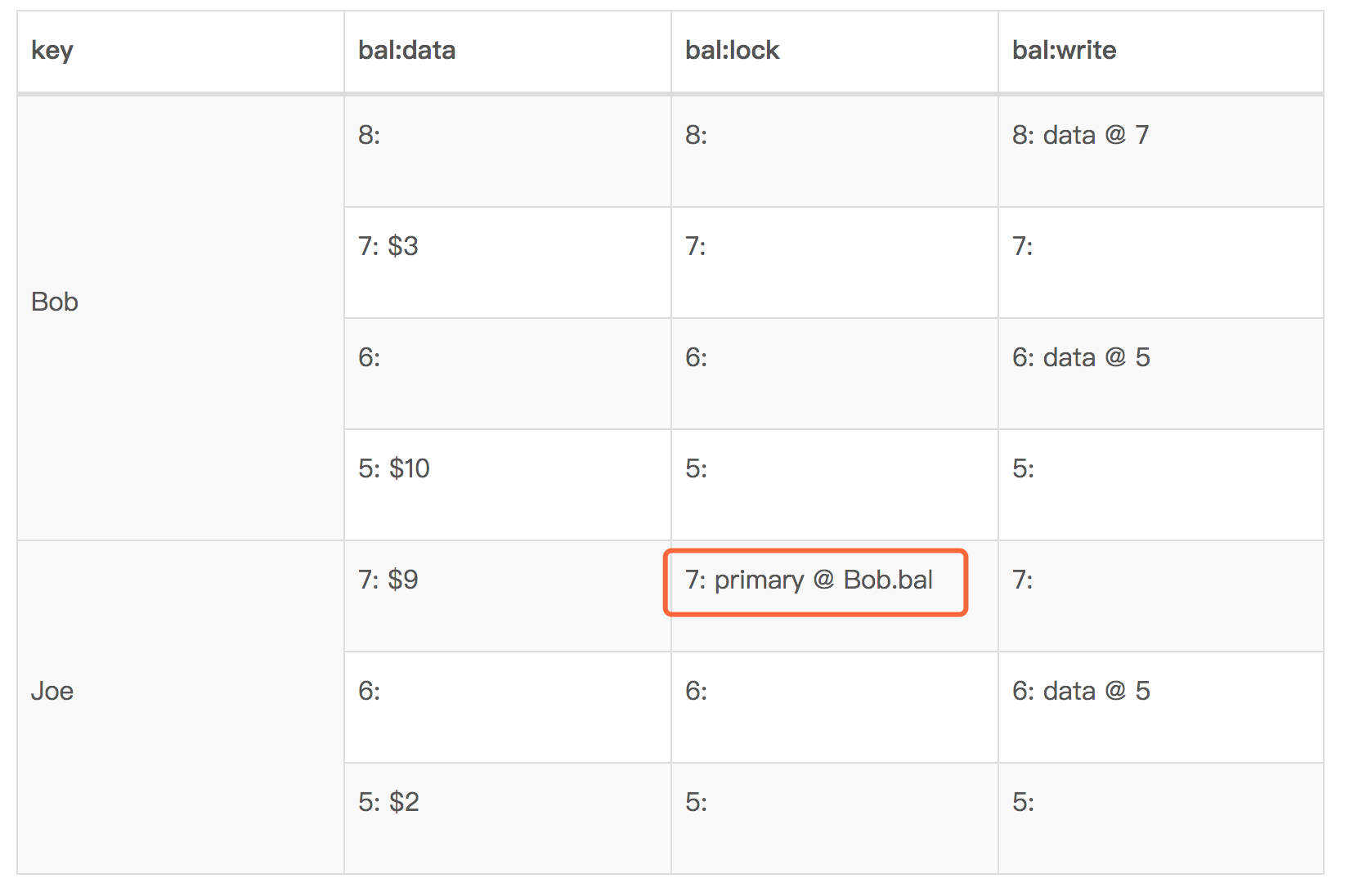
Google Percolator模型也有一些已知缺陷:提交阶段延迟较高,仅支持乐观锁场景、冲突错误只能在提交时汇报等。这与传统的关系数据库基于悲观事务的模型以及秒杀更新性能的还是有比较大的区别。
Omid模型
Omid模型是Yahoo的作品,同样也是构建在类似HBase的KV基础上,但和Percolator的Pessimistic方法相比,Omid是一种Optimistic的方式,正如其名《Optimistically transaction Management In Datastores》。其架构相对优雅简洁,工程化做得也不错,近几年接连在ICDE、FAST、PVLDB上发了多篇论文。
Omid认为Percolator的基于Lock的方案虽然简化了事务冲突检查,但是将事务的驱动交给客户端,在客户端故障的情况下,遗留的Lock清理会影响到其他事务的执行,并且维护额外的lock和write列,显然也会增加不小的开销。而Omid这样的Optimistic方案完全由中心节点来决定Commit与否,强化了中心节点TSO的能力,记录一个lastCommit事务的WriteSet内容,在事务提交的validate阶段进行事务冲突判断。

Calvin模型
Calvin模型最早是在12年提出来的概念,《Calvin: Fast Distributed Transactions for Partitioned Database Systems》。相比于传统的数据库,Calvin是一个另类思维的deterministic database,对于需要处理的事务,Calvin 会在全局确定好事务的顺序,并按照这个提前确定的顺序执行。对于这些事务的执行顺序,我们可以认为是一个全局的有序 log,分布式下的多个分片只需要严格按照这个全局log进行当前分片的执行操作,每个分片的副本结合常规的主备或者Paxos/Raft复制机制保障持久化。
VoltDB是确定性数据库的工程化的典型代表,经过研究发现(《OLTP Through the Looking Glass, and What We Found There》)目前数据库事务只有不到10~20%的指令代价在处理数据本身,其余的大部分都是在锁管理、WAL、缓存管理上。因此,VoltDB设计为一个确定性的全内存数据库,基于确定性的事务配合串行化的执行,规避了事务并发的大部分开销,从而可以达到单机50万+的性能。
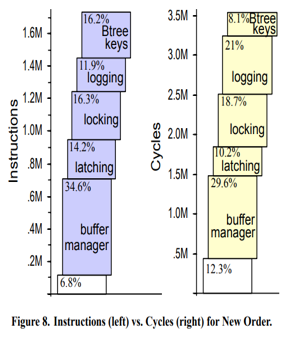
VoltDB具体的实现细节网上已有蛮多的文章介绍,其另一个最大的设计上引入了可编程的存储过程,把交互式的事务设计的业务逻辑一次性打包发送到数据库上,由数据库进行确定性定序和执行。
XA模型
XA 协议全名为 X/Open XA 协议,是一项通用的事务接口标准,最早在90年代开始提出。
X/OPEN是一个组织,它在规范中定义了分布式事务处理模型,简称DTP(X/Open Distributed Transaction Processing Reference Model)。该DTP模型中,主要包含3种角色:AP(Application,应用程序)、RM(resouces manager资源管理器,通常指单个数据分片)、TM(transaction manager事务管理器,通常指事务协调者,提供给AP变成接口以及管理资源管理器)。
XA 协议则是在DTP模型下定义的一套标准交互接口,比如常见的有:xa_start、xa_end、xa_commit、xa_rollback等。目前主流的商业数据库基本都实现了XA协议,比如Oracle、MySQL等。
XA 协议主要基于2PC两阶段提交实现事务的原子性,而分布式下的一致性则需要更多的设计。以MySQL XA为例,如果应用DTP模型的分布式交互,需要将MySQL的隔离级别调整为serializable才可以满足一致性的要求,主要的原因是分布式下MySQL还是基于serializable对读加锁来提供了分布式的一致性,因此会有比较大的性能影响。

在分布式场景下,目前主流优化DTP模型下的分布式一致性技术,主要就是分布式MVCC(可以看下传统数据库的发展),在MVCC的实现上目前主要有两种架构:
- GTM(全局事务管理)+MVCC。最典型的代表就是PGXC,其设计上是引入了全局活跃事务链表,每个分布式事务开始和结束都需要和GTM进行交互,维护一个分布式的全局活跃链表。在数据存储上引入多版本的技术,可以满足分布式下的MVCC一致性。
- TSO(全局时钟服务)+MVCC。最典型的代表就是PolarDB-X,设计上引入全局时钟服务,配合数据存储的多版本技术,可以满足强一致的事务要求。
PolarDB-X 分布式事务
使用体验
终于进入正题,我们来看一下PolarDB-X如何支持分布式事务。
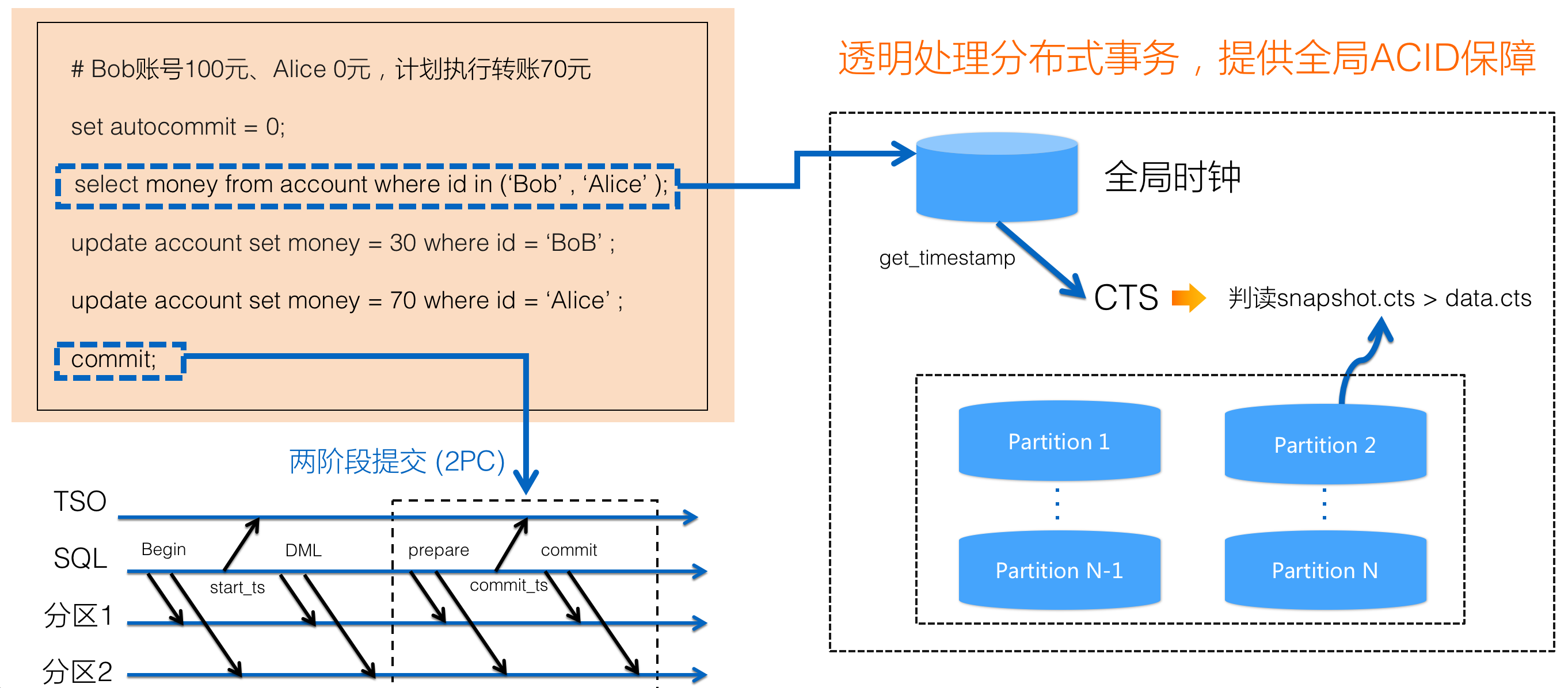
首先看一下PolarDB-X面向用户的使用,可以完全和单机的事务模型保持一致。
实现技术
PolarDB-X分布式事务的主要技术:
- 持久性:Paxos
- 原子性:2PC + XA
- 隔离性 & 一致性:TSO + MVCC
我们简单来分解一下技术,并做一下实现解读。
Paxos
PolarDB-X的存储引擎主要基于WAL + 多数派Paxos协议。
PolarDB-X分布式事务中涉及到的每个DN节点都会有多副本的支持,在返回用户事务提交成功后,如果有异常掉电、硬盘异常等场景,可以通过Paxos多数派机制自动完成切换,可满足RPO=0,在数据库节点重启恢复时,结合WAL的日志可以确保恢复到正确的状态。
2PC + XA
PolarDB-X是存储计算分离的设计,分布式DTP模型里的RM模型就是PolarDB-X里的存储节点DN,TM模型就是PolarDB-X里的计算节点CN。
PolarDB-X DN通过Paxos保证了服务的高可用,CN本身不存储数据,它是一个无状态的服务,可以通过常规的负载均衡设备提供高可用能力,比如Lvs/HaProxy/F5等。每个应用AP发起的分布式事务,路由到了其中一个CN后,当前这个CN就会承担着当前事务的TM角色的工作,负责事务状态和日志的跟踪,会持久化事务日志。如果当前CN故障后,会由另外的CN节点基于持久化的事务日志进行接管,解决2PC协议中的TM状态不一致问题。
PolarDB-X CN节点(作为TM事务管理器),会通过XA协议接口和PolarDB-X DN节点(作为RM资源管理器)进行事务交互,比如在事务提交时,会有如下的交互流程:
- CN节点在接收到用户客户端的事务commit事件
- CN节点对所有事务参与DN分片,发起第一轮的xa prepare交互 (确认所有的参与者是否认可当前事务的提交,如果认可提交则需要持久化部分的状态到WAL,保证持久性)
- CN节点收到所有DN返回prepare ok后,发起第二轮的xa commit交互 (提交每个DN节点事务的中间状态)
2PC流程整体不算复杂,但需要重点考虑故障容错,比如用户请求、CN节点、DN节点在各个环节多会有异常crash的风险。PolarDB-X目前结合CN/DN本身的高可用设计,可以很好地支持2PC的故障容错。
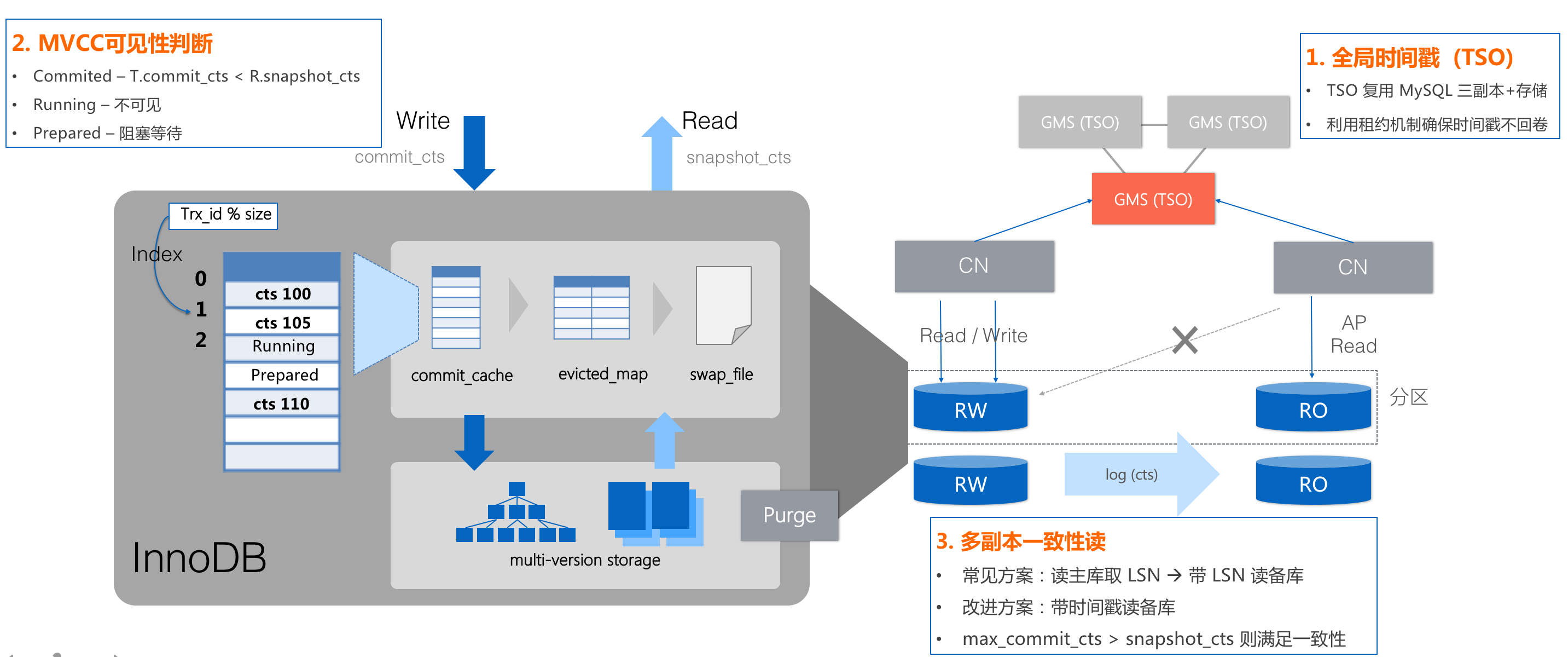
TSO + MVCC
全局时钟需要一个生成全局单调递增 Timestamp 的策略,常见的策略有 True Time(Google Spanner)、HLC(CockroachDB)、TSO(TiDB),我们目前的实现中使用了 TSO 策略,由 GMS(元数据管理服务)作为一个三节点的高可用服务承担生成 Timestamp 的任务。TSO 保证了正确的线性一致性和良好的性能,只是在跨全球机房部署的场景会带来较高的延迟,后续我们也会有文章专门介绍跨机房部署下的TSO优化策略。
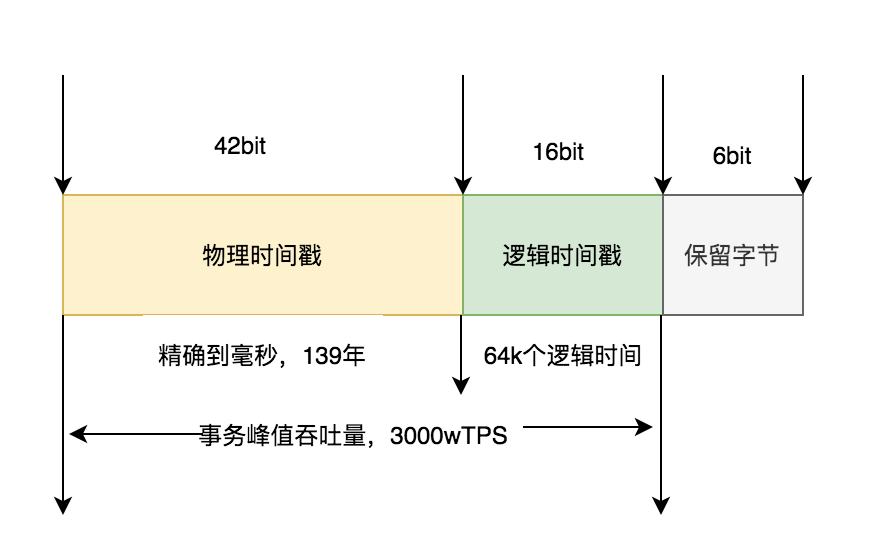
时间戳格式
时间戳格式采用物理时钟+逻辑时钟方式,物理时钟精确到毫秒。

MVCC
我们在MySQL的单机MVCC多版本基础上,扩展支持了分布式的MVCC能力,我们在MySQL存储上除了其自有的txid基础上,新增了commit timestamp的概念(简称cts),这个cts的内容都是由PolarDB-X CN节点在做事务操作时传递给PolarDB-X DN节点,在write操作中写入到存储,在read操作时带着一个查询的cts和存储记录里的cts做大小比较,最终决定数据的可见性。
我们除了在PolarDB-X DN节点的leader主副本中保存cts信息之外,也会将存储带cts的信息同步到follower/learner副本中,这样可以很好地支持多副本的一致性读。比如,我在主副本里写入了一个cts=100的数据,我在下一次的查询中带着cts=101,查询路由到只读的learner节点,即使learner节点有数据复制延迟,我们也可以实现阻塞读来满足一致性。这部分的技术优化,将会在后续的PolarDB-X HTAP技术细节中深度展开。
总结
PolarDB-X经历阿里集团多年双十一的技术积累和稳定性验证,在强一致分布式事务中,我们也做了非常多的技术选型和优化,比如热点事务、跨机房2PC优化、HTAP混合负载等。云的未来已来,我们已经在路上,欢迎大家加入我们 !
